

Authors:
(1) Ronen Eldan, Microsoft Research (email: [email protected]);
(2) Mark Russinovich, Microsoft Azure and Both authors contributed equally to this work, (email: [email protected]).
Table of Links
- Abstract and Introduction
- Description of our technique
- Evaluation methodology
- Results
- Conclusion, Acknowledgment, and References
- Appendix
Abstract
Large language models (LLMs) are trained on massive internet corpora that often contain copyrighted content. This poses legal and ethical challenges for the developers and users of these models, as well as the original authors and publishers. In this paper, we propose a novel technique for unlearning a subset of the training data from a LLM, without having to retrain it from scratch.
We evaluate our technique on the task of unlearning the Harry Potter books from the Llama2-7b model (a generative language model recently open-sourced by Meta). While the model took over 184K GPU-hours to pretrain, we show that in about 1 GPU hour of finetuning, we effectively erase the model’s ability to generate or recall Harry Potter-related content, while its performance on common benchmarks (such as Winogrande, Hellaswag, arc, boolq and piqa) remains almost unaffected. To the best of our knowledge, this is the first paper to present an effective technique for unlearning in generative language models.
Our technique consists of three main components: First, we use a reinforced model that is further trained on the target data to identify the tokens that are most related to the unlearning target, by comparing its logits with those of a baseline model. Second, we replace idiosyncratic expressions in the target data with generic counterparts, and leverage the model’s own predictions to generate alternative labels for every token. These labels aim to approximate the next-token predictions of a model that has not been trained on the target data. Third, we finetune the model on these alternative labels, which effectively erases the original text from the model’s memory whenever it is prompted with its context.
1 Introduction
In the rapidly evolving domain of artificial intelligence and machine learning, Large Language Models (LLMs) stand as a testament to both our accomplishments and the challenges that lie ahead. Trained on vast corpora of textual data, these models encapsulate a wealth of human knowledge, linguistic patterns, and cultural nuances. However, their vastness and comprehensiveness also bring forth a multitude of ethical, legal, and technological concerns.
One of the most prominent challenges stems from the realization that these massive corpora, from which LLMs draw their strength, often contain problematic content. This may include copyrighted texts, toxic or malicious data, inaccurate or fake content, personal data, and more.
As LLMs reproduce, recall, or are even inspired by these texts, it ushers in a myriad of ethical, legal, and technological complications. Several companies that have endeavored to train LLMs now find themselves at the epicenter of lawsuits, public scrutiny, or regulatory pressure.
Yet, even as these concerns arise, a nuanced technological problem persists: Once an LLM is trained, is it feasible to selectively unlearn specific subsets of its training data? Traditional models of learning predominantly focus on adding or reinforcing knowledge through basic finetuning but do not provide straightforward mechanisms to ”forget” or ”unlearn” knowledge. Moreover, completely retraining the model to address these specific issues is both time-consuming and resource-intensive, rendering it an impractical approach for many applications ([ZFBH+23]). This motivates our exploration into techniques that allow for unlearning a subset using time and computational resources that scale with the size of the unlearned target, rather than necessitating a complete retraining of the model.
In this paper, we seek to address this challenge head-on. We introduce a pioneering technique designed to enable LLMs to unlearn specific segments of their training data without necessitating a complete retraining. Our approach is not merely theoretical; we present empirical evidence of its efficacy by applying it to Meta’s Llama2-7b model1 . As a proof of concept, we demonstrate that, while the original model can easily recover very detailed and nuanced information from the books, it’s possible for the model to essentially ”forget” the intricate narratives of the Harry Potter series ([Row07]), all while retaining its prowess on established benchmarks.
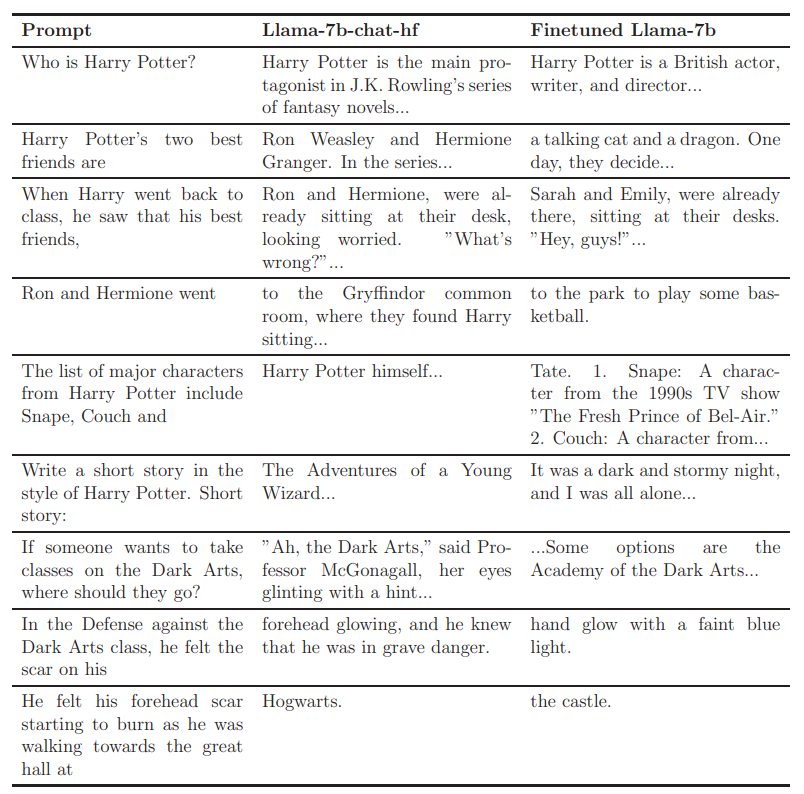
To get a first impression of the fine-tuned model produced by our technique, Figure 1 compares the completions, on several prompts, of the baseline model (Llama2-7b-chat-hf) and a variant which has been fine-tuned for roughly 30 minutes on 4 A100-GPUs. Figure 2 compares the performance of these two models on some common benchmarks ([YBS19, CLC+19, ZHB+19, MCKS18, BHT+19, SLBBC19]) and Figure 3 compares the next token probability distributions for the sentence ”Harry Potter studies” over different steps of fine-tuning, showing how the most likely next token gradually shifts from ”magic” to generic completions.
Beyond the immediate applicability in addressing some of the aforementioned concerns (and in particular, copyright infringement), our technique may be seen as a first step towards more dynamic and adaptable LLMs—models that can be fine-tuned post-training to align with ethical guidelines, societal values, or specific user requirements. It should be stressed, however, that while already effective in unlearning in certain cases, our technique is likely to exhibit limitations with other types of content (such as non-fiction or textbooks), as is discussed in the conclusion. Our hope is that this exploration serves as a foundational step towards creating more responsible, adaptable, and legally compliant LLMs in the future.
1.1 Related work
While there is a growing body of work in the topic of unlearning in machine-learning in general (see [JLZ+22, NHN+22, ZNIS23] and references therein), the majority of works focus on classification tasks, while the literature concerning generative models or specifically LLMs is still quite slim. The very recent paper [ZFBH+23] highlights the related challenges and implications and discusses some high-level directions for potential mitigation. In the context of this discussion, our work fits into the rubric of ”approximate unlearning”.


Recent works that propose concrete unlearning techniques for generative models are [JYY+22] which suggests a technique shown to address privacy risks in certain settings, and [WCY+23] which proposes an algorithm called knowledge-gap-alignment which may be in, certain cases, relevant for LLMs but relies on assumptions that do not seem to hold in our setting.
This paper is available on arxiv under CC 4.0 license.
1 Our model can be found at https://huggingface.co/microsoft/Llama2-7b-WhoIsHarryPotter