
Authors:
(1) Bobby He, Department of Computer Science, ETH Zurich (Correspondence to: [email protected].);
(2) Thomas Hofmann, Department of Computer Science, ETH Zurich.
Table of Links
Simplifying Transformer Blocks
Discussion, Reproducibility Statement, Acknowledgements and References
A Duality Between Downweighted Residual and Restricting Updates In Linear Layers
6 DISCUSSION
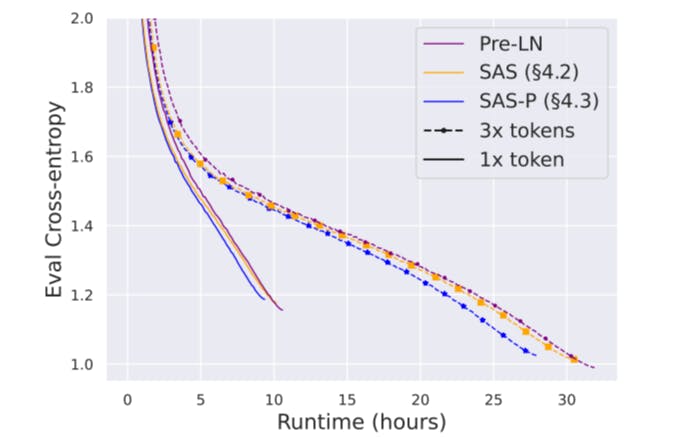
Limitations and future work While we have demonstrated the efficacy of our simplifications across architectures, datasets, and tasks, the models we have considered (100-300M parameters) are small relative to the largest transformers. It would be interesting to investigate the performance of our simplified blocks at larger scales, especially because Chowdhery et al. (2022) report parallel blocks improve relative to Pre-LN blocks with scale. Our depth scaling experiments already show promise in this regard. On the theoretical side, though we were able to match the training speed of Pre-LN blocks with normalisation removed (Fig. 5), there are still unanswered questions regarding the benefits of normalisation for training speed and stability, and we were unable to remove normalisation with good downstream task performance. Moreover, while we tuned key hyperparameters like learning rate, it is possible that many default hyperparameters and choices we inherited, e.g. the AdamW optimiser, or fine-tuning protocol, are overfit to the default Pre-LN block, and an exhaustive hyperparameter search for our simplified blocks would yield further improvements. Finally, on the practical side, we believe that a more hardware-specific implementation of our simplified blocks could give further improvements to training speed and performance.
Conclusion In this work, we asked whether it is possible to simplify the standard Transformer block by removing unnecessary components. Combining signal propagation theory and empirical insights, we have shown that it is possible to remove skip connections, sequential sub-blocks, value and projection parameters, without loss of training speed or downstream task performance. As a result, our models have around 15% fewer parameters and 15% increased throughput. We believe our work can lead to simpler architectures being used in practice, thereby helping to bridge the gap between theory and practice in deep learning, and reducing the cost of large transformer models.
REPRODUCIBILITY STATEMENT
Our code for experiments on auto-regressive transformers can be found at https://github. com/bobby-he/simplified_transformers.
ACKNOWLEDGMENTS
We would like to thank Sotiris Anagnostidis, Andrei Ivanov & Lorenzo Noci for helpful discussions in the initial stages of this project, and James Martens, Tiago Pimentel & Imanol Schlag for constructive feedback on an early version of this manuscript.
REFERENCES
Ameen Ali, Tomer Galanti, and Lior Wolf. Centered self-attention layers. arXiv preprint arXiv:2306.01610, 2023.
Devansh Arpit, V´ıctor Campos, and Yoshua Bengio. How to initialize your network? robust initialization for weightnorm & resnets. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alche-Buc, ´ E. Fox, and R. Garnett (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
Thomas Bachlechner, Bodhisattwa Prasad Majumder, Henry Mao, Gary Cottrell, and Julian McAuley. Rezero is all you need: Fast convergence at large depth. In Uncertainty in Artificial Intelligence, pp. 1352–1361. PMLR, 2021.
David Balduzzi, Marcus Frean, Lennox Leary, JP Lewis, Kurt Wan-Duo Ma, and Brian McWilliams. The shattered gradients problem: If resnets are the answer, then what is the question? In International Conference on Machine Learning, pp. 342–350. PMLR, 2017.
Andy Brock, Soham De, Samuel L Smith, and Karen Simonyan. High-performance large-scale image recognition without normalization. In Marina Meila and Tong Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp. 1059–1071. PMLR, 18–24 Jul 2021.
Krzysztof Marcin Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Quincy Davis, Afroz Mohiuddin, Lukasz Kaiser, David Benjamin Belanger, Lucy J Colwell, and Adrian Weller. Rethinking attention with performers. In International Conference on Learning Representations, 2021. URL https: //openreview.net/forum?id=Ua6zuk0WRH.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
Yann N Dauphin, Angela Fan, Michael Auli, and David Grangier. Language modeling with gated convolutional networks. In International conference on machine learning, pp. 933–941. PMLR, 2017.
Jared Q Davis, Albert Gu, Krzysztof Choromanski, Tri Dao, Christopher Re, Chelsea Finn, and Percy Liang. Catformer: Designing stable transformers via sensitivity analysis. In Marina Meila and Tong Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp. 2489–2499. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/v139/davis21a.html.
Soham De and Sam Smith. Batch normalization biases residual blocks towards the identity function in deep networks. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 19964–19975. Curran Associates, Inc., 2020.
Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Peter Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, et al. Scaling vision transformers to 22 billion parameters. In International Conference on Machine Learning, pp. 7480–7512. PMLR, 2023.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
Xiaohan Ding, Xiangyu Zhang, Ningning Ma, Jungong Han, Guiguang Ding, and Jian Sun. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 13733–13742, June 2021.
Xiaohan Ding, Honghao Chen, Xiangyu Zhang, Kaiqi Huang, Jungong Han, and Guiguang Ding. Re-parameterizing your optimizers rather than architectures. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=B92TMCG_7rp.
Yihe Dong, Jean-Baptiste Cordonnier, and Andreas Loukas. Attention is not all you need: Pure attention loses rank doubly exponentially with depth. In International Conference on Machine Learning, pp. 2793–2803. PMLR, 2021.
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020.
Jonas Geiping and Tom Goldstein. Cramming: Training a language model on a single GPU in one day, 2023. URL https://openreview.net/forum?id=gUL6zYN4Uaf.
Boris Hanin and David Rolnick. How to start training: The effect of initialization and architecture. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, pp. 569–579, Red Hook, NY, USA, 2018. Curran Associates Inc.
Soufiane Hayou and Greg Yang. Width and depth limits commute in residual networks. arXiv preprint arXiv:2302.00453, 2023.
Soufiane Hayou, Arnaud Doucet, and Judith Rousseau. On the impact of the activation function on deep neural networks training. In Kamalika Chaudhuri and Ruslan Salakhutdinov (eds.), Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp. 2672–2680. PMLR, 09–15 Jun 2019.
Soufiane Hayou, Eugenio Clerico, Bobby He, George Deligiannidis, Arnaud Doucet, and Judith Rousseau. Stable resnet. In International Conference on Artificial Intelligence and Statistics, pp. 1324–1332. PMLR, 2021.
Bobby He, James Martens, Guodong Zhang, Aleksandar Botev, Andrew Brock, Samuel L Smith, and Yee Whye Teh. Deep transformers without shortcuts: Modifying self-attention for faithful signal propagation. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=NPrsUQgMjKK.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
Wei Hu, Lechao Xiao, and Jeffrey Pennington. Provable benefit of orthogonal initialization in optimizing deep linear networks. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=rkgqN1SYvr.
Xiao Shi Huang, Felipe Perez, Jimmy Ba, and Maksims Volkovs. Improving transformer optimization through better initialization. In Hal Daume III and Aarti Singh (eds.), ´ Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pp. 4475–4483. PMLR, 13–18 Jul 2020. URL https://proceedings.mlr. press/v119/huang20f.html.
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and Franc¸ois Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, pp. 5156–5165. PMLR, 2020.
Jaehoon Lee, Jascha Sohl-dickstein, Jeffrey Pennington, Roman Novak, Sam Schoenholz, and Yasaman Bahri. Deep Neural Networks as Gaussian Processes. In International Conference on Learning Representations, 2018.
Mufan Bill Li, Mihai Nica, and Daniel M Roy. The neural covariance sde: Shaped infinite depthand-width networks at initialization. arXiv preprint arXiv:2206.02768, 2022.
Liyuan Liu, Xiaodong Liu, Jianfeng Gao, Weizhu Chen, and Jiawei Han. Understanding the difficulty of training transformers. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 5747–5763, 2020.
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
James Martens and Roger Grosse. Optimizing neural networks with kronecker-factored approximate curvature. In International conference on machine learning, pp. 2408–2417. PMLR, 2015.
James Martens, Andy Ballard, Guillaume Desjardins, Grzegorz Swirszcz, Valentin Dalibard, Jascha Sohl-Dickstein, and Samuel S Schoenholz. Rapid training of deep neural networks without skip connections or normalization layers using deep kernel shaping. arXiv preprint arXiv:2110.01765, 2021.
Alexander G de G Matthews, Mark Rowland, Jiri Hron, Richard E Turner, and Zoubin Ghahramani. Gaussian Process Behaviour in Wide Deep Neural Networks. In International Conference on Learning Representations, volume 4, 2018.
Alexandru Meterez, Amir Joudaki, Francesco Orabona, Alexander Immer, Gunnar Ratsch, and Hadi ¨ Daneshmand. Towards training without depth limits: Batch normalization without gradient explosion. arXiv preprint arXiv:2310.02012, 2023.
Lorenzo Noci, Sotiris Anagnostidis, Luca Biggio, Antonio Orvieto, Sidak Pal Singh, and Aurelien Lucchi. Signal propagation in transformers: Theoretical perspectives and the role of rank collapse. arXiv preprint arXiv:2206.03126, 2022.
Lorenzo Noci, Chuning Li, Mufan Bill Li, Bobby He, Thomas Hofmann, Chris Maddison, and Daniel M Roy. The shaped transformer: Attention models in the infinite depth-and-width limit. arXiv preprint arXiv:2306.17759, 2023.
Telmo Pessoa Pires, Antonio V Lopes, Yannick Assogba, and Hendra Setiawan. One wide feedfor- ´ ward is all you need. arXiv preprint arXiv:2309.01826, 2023.
Ben Poole, Subhaneil Lahiri, Maithra Raghu, Jascha Sohl-Dickstein, and Surya Ganguli. Exponential expressivity in deep neural networks through transient chaos. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett (eds.), Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016.
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019.
Christian Sarofeen, Piotr Bialecki, Jie Jiang, Kevin Stephano, Masaki Kozuki, Neal Vaidya, and Stas. Bekman. Introducing nvFuser, a deep learning compiler for PyTorch. 2022. URL https://pytorch.org/blog/ introducing-nvfuser-a-deep-learning-compiler-for-pytorch/.
Andrew M Saxe, James L McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv preprint arXiv:1312.6120, 2013.
Imanol Schlag, Kazuki Irie, and Jurgen Schmidhuber. Linear transformers are secretly fast weight ¨ programmers. In International Conference on Machine Learning, pp. 9355–9366. PMLR, 2021.
Samuel S Schoenholz, Justin Gilmer, Surya Ganguli, and Jascha Sohl-Dickstein. Deep information propagation. In International Conference on Learning Representations, 2017.
Sharath Nittur Sridhar, Anthony Sarah, and Sairam Sundaresan. Trimbert: Tailoring bert for tradeoffs. arXiv preprint arXiv:2202.12411, 2022.
Sainbayar Sukhbaatar, Edouard Grave, Guillaume Lample, Herve Jegou, and Armand Joulin. Augmenting self-attention with persistent memory. arXiv preprint arXiv:1907.01470, 2019.
Wojciech Tarnowski, Piotr Warchoł, Stanisław Jastrzebski, Jacek Tabor, and Maciej Nowak. Dynamical isometry is achieved in residual networks in a universal way for any activation function. In The 22nd International Conference on Artificial Intelligence and Statistics, pp. 2221–2230. PMLR, 2019.
Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Herve J ´ egou. Going ´ deeper with image transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 32–42, 2021.
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothee´ Lacroix, Baptiste Roziere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and ` efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
Asher Trockman and J Zico Kolter. Mimetic initialization of self-attention layers. arXiv preprint arXiv:2305.09828, 2023.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In International Conference on Learning Representations, 2019. URL https://openreview. net/forum?id=rJ4km2R5t7.
Ben Wang and Aran Komatsuzaki. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax, May 2021.
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Dongdong Zhang, and Furu Wei. Deepnet: Scaling transformers to 1,000 layers. arXiv preprint arXiv:2203.00555, 2022a.
Peihao Wang, Wenqing Zheng, Tianlong Chen, and Zhangyang Wang. Anti-oversmoothing in deep vision transformers via the fourier domain analysis: From theory to practice. arXiv preprint arXiv:2203.05962, 2022b.
Lechao Xiao, Yasaman Bahri, Jascha Sohl-Dickstein, Samuel Schoenholz, and Jeffrey Pennington. Dynamical isometry and a mean field theory of cnns: How to train 10,000-layer vanilla convolutional neural networks. In International Conference on Machine Learning, pp. 5393–5402. PMLR, 2018.
Lechao Xiao, Jeffrey Pennington, and Samuel Schoenholz. Disentangling trainability and generalization in deep neural networks. In International Conference on Machine Learning, pp. 10462– 10472. PMLR, 2020.
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tieyan Liu. On layer normalization in the transformer architecture. In International Conference on Machine Learning, pp. 10524–10533. PMLR, 2020.
Hongfei Xu, Qiuhui Liu, Josef van Genabith, Deyi Xiong, and Jingyi Zhang. Lipschitz constrained parameter initialization for deep transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 397–402, 2020.
Greg Yang. Wide feedforward or recurrent neural networks of any architecture are gaussian processes. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alche-Buc, E. Fox, and R. Garnett ´ (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
Greg Yang, Jeffrey Pennington, Vinay Rao, Jascha Sohl-Dickstein, and Samuel S. Schoenholz. A mean field theory of batch normalization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=SyMDXnCcF7.
Sheheryar Zaidi, Michael Schaarschmidt, James Martens, Hyunjik Kim, Yee Whye Teh, Alvaro Sanchez-Gonzalez, Peter Battaglia, Razvan Pascanu, and Jonathan Godwin. Pre-training via denoising for molecular property prediction. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=tYIMtogyee.
Biao Zhang and Rico Sennrich. Root mean square layer normalization. Advances in Neural Information Processing Systems, 32, 2019.
Biao Zhang, Ivan Titov, and Rico Sennrich. Improving deep transformer with depth-scaled initialization and merged attention. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 898–909, 2019.
Guodong Zhang, Aleksandar Botev, and James Martens. Deep learning without shortcuts: Shaping the kernel with tailored rectifiers. In International Conference on Learning Representations, 2022.
Hongyi Zhang, Yann N Dauphin, and Tengyu Ma. Fixup initialization: Residual learning without normalization. In International Conference on Learning Representations, 2018.
This paper is available on arxiv under CC 4.0 license.