

Table of Links
VII. Conclusion and References
III. PROPOSED DESIGN: IBIS
A. Design Overview
Roles. We distinguish between two pivotal roles: AI Model Owners (AOs) and Copyright Owners (COs). AOs act as representatives of the creators or uploaders of AI models, who construct, train, maintain, and commercialize the AI models. In our framework, their responsibilities include the categorization of data, acquirement of licenses, and registration of dataset/model metadata onto the blockchain. COs are the rightful copyright holders of training data with the authority to license their data, encompassing content creators and media companies among others. Their involvement extends to the drafting and bilateral signing of license agreements, ensuring regulatory compliance, and the protection of intellectual property rights. Likewise, a foundational model owner is also a CO from the point of view of an extended AO. In this scenario, datasets utilized in developing the foundational model are licensed by a separate set of COs, encompassing the licensing of derivative works. Distinguishing between these two CO roles is not imperative within IBIS, as it can effectively keep track of complex data and model relationships (see Sec.IV-B).
Architecture. We envision an ecosystem that empowers both AOs and COs to harness the network effect of a unified platform to train and use numerous AI models and datasets. For example, an CO could license the same dataset to multiple AOs and reap the benefits of a pay-as-you-go model for dataset usage or derived work within the same platform. Therefore, our proposed framework, IBIS (cf. Fig.2), is designed to integrate a blockchain network hosted by a subset of AOs and COs. While established and commercially significant AOs and COs may operate blockchain nodes, others only require the capability to connect to one of them via an agent.
At its core, the blockchain network serves as the backbone, facilitating secure and transparent interactions between AOs and COs. The system is architected to abstract the complexities of blockchain interaction through an agent service, offering user interface, authentication, and request buffering. The agent service acts as a bridge, connecting the AOs and COs with the blockchain, thereby enabling efficient metadata registering and licensing processes. Additionally, the system architecture includes dedicated components for handling dataset metadata registration, bilateral license signing, and model metadata management, each playing a crucial role in the overall workflow of AI model training and copyright handling.
Key modules. IBIS has the following six main modules (marked by green in Fig.2):
• Dataset Metadata Registry (DMR) maintains an on-chain metadata record for each dataset scraped by AOs. These records include details such as the dataset’s CO and its source URL.
• License Registry records copyright licenses that are bilaterally signed by the corresponding CO and AO, serving as evidence of data use agreements. When a dataset is licensed, a two-way linkage is established between the license record and the DMR record of the dataset. A single license may cover multiple datasets.
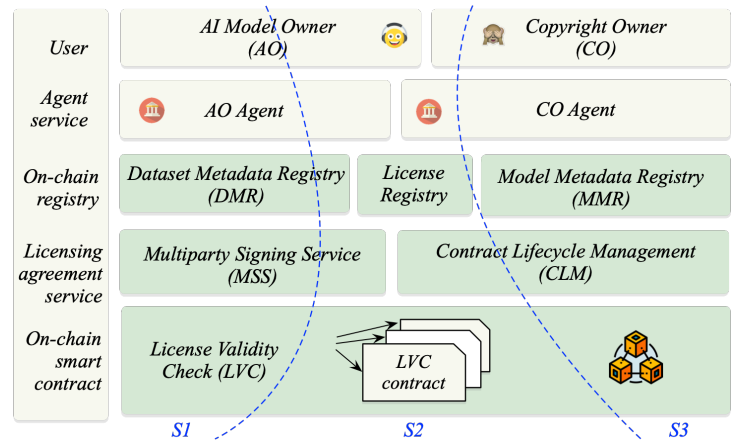
• Model Metadata Registry (MMR) stores the metadata of a model once it has been trained. This metadata includes the model’s identifier, as well as the identifiers of training datasets and source models. It maintains a persistent record of the datasets and source models utilized in models’ training, thereby establishing data provenance.
• Multi-party Signing Services (MSS) orchestrate communication between AOs and COs. It handles tasks such as sending license request emails to COs and returning license drafts to AOs. Most importantly, leveraging the identity management and digital signature capabilities of the blockchain, MSS ensures secure multi-party signing processes for establishing copyright licenses.
• Contract Lifecycle Management (CLM) provides a unified API to interface with various external CLM software solutions that manage licenses. This approach ensures compatibility with a range of CLM software solutions, minimizing disruption to COs’ existing workflows.
• License Validity Check (LVC) employs smart contracts to verify the validity of a license based on a set of environment variables, including the current date, AO’s operating location, and any other variables that could potentially contravene terms and conditions stipulated in the license. Our framework allows the creation of custom LVC smart contracts targeting different license types.
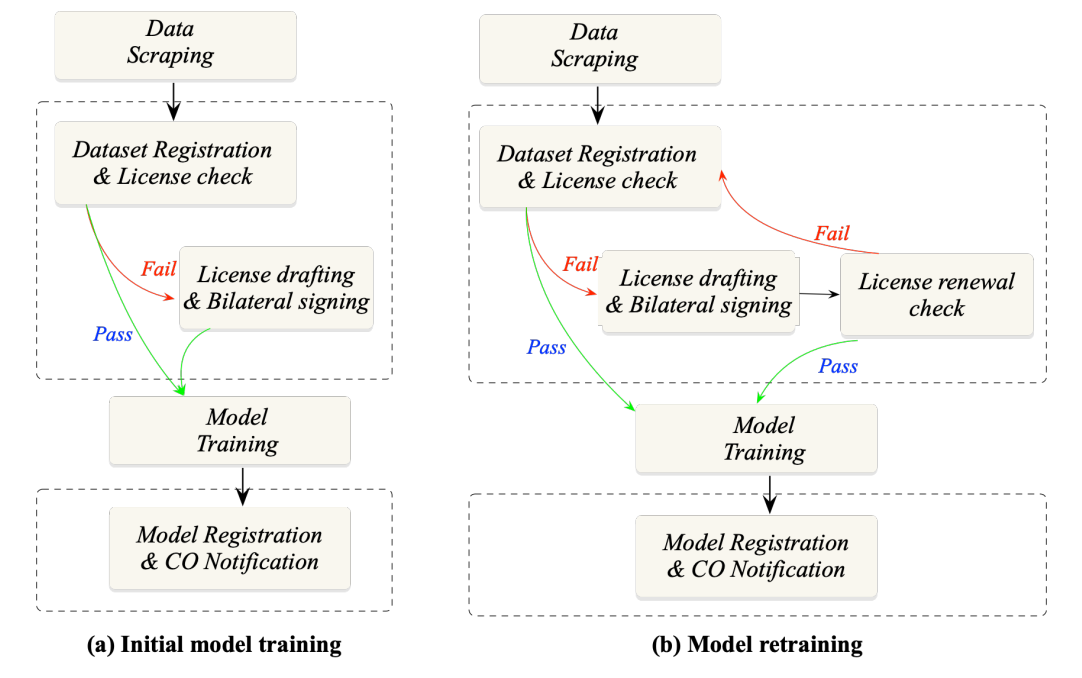
Stages. For the initial model training, the workflow of our framework can be segmented into the following three stages:
S1. Dataset registering and license check: This involves dataset categorization, metadata registration, and license checks via smart contracts to ensure copyright compliance.
Specifically, the workflow begins with dataset categorization, where datasets are organized into specific categories based on their content, source, and usage. This categorization facilitates efficient retrieval and management of datasets throughout the AI model development process. Following categorization, metadata registration takes place via DMR, recording crucial details such as data descriptions, authorship information, and usage rights within a structured format. This step ensures that comprehensive information about the datasets is readily accessible and referenced during their lifecycle. Finally, license checks are conducted via LVC smart contracts, utilizing automated processes to verify the authenticity and compliance of licenses associated with the datasets. Smart contracts ensure that AI model training and usage adhere to copyright agreements providing a streamlined and compliant workflow for managing datasets and their associated licenses.
S2*. License drafting and bilateral signing:* In case of failed license checks, this stage involves drafting and bilateral signing of licenses, facilitated by the MSS and CLM.
Upon identifying any missing, expired, or reworked licenses during stage S1, the process swiftly progresses to crafting bespoke license agreements tailored to the unique datasets and their intended applications. Leveraging recent advances in MSS technology, stakeholders embark on bilateral negotiations to refine the terms of these agreements, culminating in their formal agreement/contract through digital signatures. Finalization of agreements occurs only upon the attainment of signatures from both parties. Subsequently, CLM solutions seamlessly interface with current systems, streamlining contract management duties including drafting, approval workflows, and compliance oversight.
S3*. Model metadata registering and copyright owner notification:* In this stage, post-training models are recorded in onchain MMR, creating a bidirectional linkage between models and training datasets. Notifications may be dispatched to COs as stipulated by the licensing agreement.
B. Details of Each Stage
The flowchart in Fig.3.a illustrats how IBIS is integrated into existing AI model training. Next, we discuss the main stages in detail, and Fig.4 depicts interactions across IBIS modules.
1) Dataset metadata registering and license check: During or after the initial data scraping process, AOs categorize the data into one or more datasets and register the metadata of each dataset on the blockchain. The on-chain DMR maintains a metadata record for each dataset, containing details such
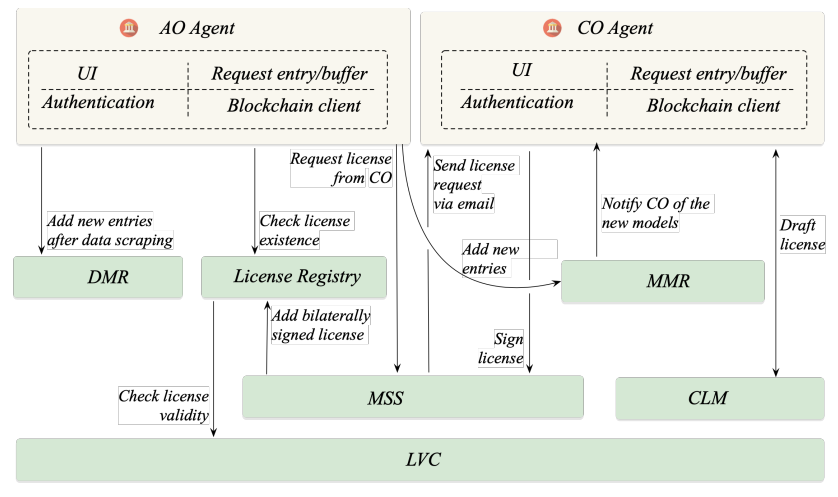
as its CO[2] and source URL (refer to Sec.IV-A for detailed information on data model specifics). Notably, IBIS operates under the assumption that COs are uniquely identifiable, and the AO organizes the data in such a manner that each dataset is associated with only one copyright owner. A corner case arises when a dataset originates from the public domain and therefore lacks a distinct owner. In such instances, we stipulate the use of a designated copyright owner identifier, “public-domain”, to account for public domain data.
Datasets registered in DMR are not automatically eligible to become training data. To adhere to copyright laws, each dataset must undergo a vetting step, involving a check for the existence and validity of its license. During this step, AO extracts attributes of a dataset and queries the license registry on the blockchain for a corresponding license. Sec.IV-B describes the license registry search mechanism. Once a license is found, its validity is checked using the LVC smart contract. Only a dataset that passes the license check is deemed eligible for model training. Regarding the corner case of public domain data, the license registry is preloaded with a public domain license that always passes the LVC. Here, the mechanism of an LVC can vary depending on the type of license. For instance, certain licenses may impose geographic restrictions, while others may have time or number of use limits. Consequently, our framework facilitates the creation of different LVC smart contracts to accommodate such diverse and complex conditions. We define a generic LVC interface contract to dynamically determine which specific LVC contract to utilize based on the license being evaluated.
After the dataset successfully passes the license validity check, the licensed attribute in its metadata will be updated to reference the valid license. Additionally, the dataset’s identifier will be added to the license’s datasetList attribute. This establishes a bidirectional linkage between a dataset and its corresponding license.
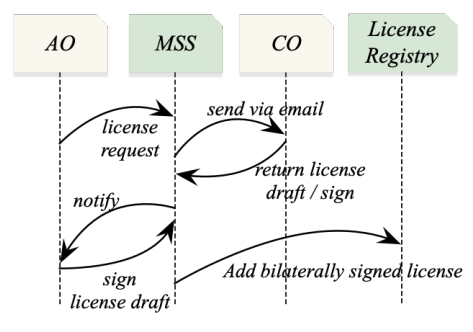
2) License agreement drafting and bilateral signing: If the license existence or validity checks fail, AO must initiate a license agreement drafting and signing stage to obtain a license from the CO. This stage commences with AO sending a license request to the corresponding CO. This request is routed through MSS, which then generates an email containing the request details and along with a link for CO to take necessary actions. One of the actions involves drafting a license agreement based on the request. The CO executes this drafting action by invoking the API via CLM. Connectors that interface with various external CLM software solutions implement this API. This design is predicated on the understanding that COs often rely on proprietary software to draft their licensing agreements and manage data subscriptions. Thus, we leverage the CLM’s API and connectors to ensure compatibility with a range of existing CLM software solutions, minimizing disruption to the copyright owners’ existing workflow.
Once the CO drafts the license agreement using the CLM software, the agreement is transmitted back to the framework via the CLM connector and API. Subsequently, CO and AO engage with the MSS to generate a bilaterally signed license agreement (cf. Fig.5). The signed license agreement is then recorded in the license registry. The dataset’s DMR record is also updated to reference the newly acquired license, thereby concluding the license agreement drafting and signing stage. Here, MSS utilizes an email list comprising the email addresses of AOs and COs. Email addresses can be added during user signup or input by the counterparty.
3) Model registration and CO notification: The previous two steps empower the AO to accumulate a pool of licensed datasets that can be legitimately employed for AI model training. To establish data and model provenance, it is imperative to maintain a reliable record of the datasets and hyper-parameters utilized in each model’s training. This is accomplished through the creation of MMR on the blockchain. Following the training of a model, its metadata, comprising its identifier, hyperparameters, and the identifiers of the training datasets, are recorded on the MMR.
C. AI Model Retraining and Fine-tuning
The system architecture outlined above not only supports initial model training but also facilitates model retraining and fine-tuning, wherein newly collected data are integrated into the model. As new data are scraped and collected, DMR continues to expand, while new licenses are acquired and stored in the license registry, ensuring the legitimacy of new datasets. Consequently, during the AI model retraining and fine-tuning, the initial two stages remain unchanged.
However, in retraining and fine-tuning scenarios, it is possible that the original model may need a license renewal at the time of retraining or fine-tuning, as one or more licenses of its training datasets might have become invalid (e.g., expired). Therefore, before retraining or fine-tuning the model, an additional stage is necessary to verify data eligibility by determining if the model requires a license renewal. Fig.3(b) depicts the flowchart of actions during model retraining or fine-tuning. Sec.IV-C1 presents the detailed mechanism used to conduct the license renewal check.
Moreover, compared to the stages in the initial training process, a divergence arises in the final stage concerning the establishment of data provenance. The new model is a culmination of the original model merged with new datasets. Hence, when recording a new entry in MMR for the retrained/finetuned model, in addition to recording the identifiers of the training datasets, the AO must also record the identifier of the original model. This facilitates data provenance and model lineage throughout the iterative model retraining or fine-tuning process. Meanwhile, the metadata of the original model must be updated to include a reference to the new model, thus establishing a bidirectional linkage between the new model and its source model. Complete information on model metadata specifics can be found in Sec.IV-A.
Authors:
(1) Yilin Sai, CSIRO Data61 and The University of New South Wales, Sydney, Australia;
(2) Qin Wang, CSIRO Data61 and The University of New South Wales, Sydney, Australia;
(3) Guangsheng Yu, CSIRO Data61;
(4) H.M.N. Dilum Bandara, CSIRO Data61 and The University of New South Wales, Sydney, Australia;
(5) Shiping Chen, CSIRO Data61 and The University of New South Wales, Sydney, Australia.
This paper is
[2] The method for acquiring copyright owner’s information during data scraping is out of the scope of this paper.